
Abstracts
Résumé
La traduction des termes complexes pose souvent des problèmes sur différents plans. D’une part, dans le texte source, ils doivent être bien identifiés et compris, puis correctement traduits. Cependant, la solution à ces problèmes ne se trouve pas toujours dans les ressources terminologiques telles que les dictionnaires ou les bases de données, de sorte que le traducteur doit recourir à d’autres outils riches en informations, comme les corpus. Pour en tirer le meilleur parti, il faut connaître les différentes méthodes d’exploitation des corpus offertes par les systèmes d’analyse actuels. Cependant, ces dernières sont souvent inconnues, ce qui génère une réticence de la part des traducteurs à utiliser des corpus (Bowker 2004 ; Gallego-Hernández 2015 ; Loock 2016). Dans cet article, nous développons un protocole pour faciliter la compréhension et la traduction des termes complexes à l’aide de corpus parallèles et comparables. Nous illustrons la procédure avec des termes complexes de l’anglais, que nous traduisons en français et en espagnol.
Mots-clés :
- terme complexe,
- traduction spécialisée,
- ressource terminologique,
- corpus parallèle,
- corpus comparable
Abstract
Translating multiword terms can pose problems at different levels. First, they need to be correctly identified and understood in the source text with a view to translating them. However, the answer to these questions cannot always be found in terminological resources such as dictionaries or databases. Therefore, translators must use other information-rich resources such as corpora. In order to make the most of them, the diverse corpus query techniques available in current corpus analysis tools must be mastered. However, these techniques are often unknown, which results in the reluctance of many translators to use corpora (Bowker 2004; Gallego-Hernández 2015; Loock 2016). This paper presents a step-by-step protocol that facilitates the comprehension and translation of multiword terms by means of parallel and comparable corpora. The procedure is illustrated with English multiword terms, which are translated into French and Spanish.
Keywords:
- multiword term,
- specialized translation,
- terminological resource,
- parallel corpus,
- comparable corpus
Resumen
La traducción de los términos compuestos puede presentar complicaciones a distintos niveles. Por una parte, en el texto origen es necesario identificarlos y comprenderlos de forma adecuada, para después trasladarlos correctamente a la lengua meta. Sin embargo, la respuesta a estas cuestiones no siempre se encuentra en los recursos terminológicos como diccionarios o bases de datos, de forma que el traductor debe recurrir a otras herramientas ricas en información como son los corpus. Para sacar el máximo partido, se deben conocer las distintas técnicas de interrogación de corpus que ofrecen los sistemas de análisis actuales. Sin embargo, estas a menudo se desconocen, lo que genera reticencia por parte de los traductores al uso de los corpus (Bowker 2004; Gallego-Hernández 2015; Loock 2016). En este artículo desarrollamos un protocolo paso a paso con el que se facilita la comprensión y traducción de los términos compuestos con la ayuda de corpus paralelos y comparables. Para ello, ilustramos el procedimiento con términos compuestos del inglés, que traducimos hacia el francés y el español.
Palabras clave:
- término compuesto,
- traducción especializada,
- recurso terminológico,
- corpus paralelo,
- corpus comparable
Article body
1. Introduction
Le traitement des termes complexes (p. ex. UV-absorbing aerosol) est l’un des grands défis de tout projet de traduction (Kübler, Mestivier et al. 2018). Évidemment, la première étape pour faciliter leur compréhension et leur traduction consiste à consulter des ressources terminologiques. Néanmoins, leur traitement et leur représentation dans ces ressources sont peu systématiques, voire inexistants. Le traducteur doit ainsi maîtriser les techniques d’interrogation de corpus pour faire face au défi de l’équivalence.
Traditionnellement, les traducteurs utilisent des textes parallèles pour l’extraction de terminologie et pour la documentation. Les textes parallèles fournissent des informations sur les conventions textuelles et les usages linguistiques d’un domaine par rapport au texte source (TS). Ils ne doivent pas être confondus avec les corpus parallèles, constitués de traductions alignées. Aujourd’hui, ces textes parallèles peuvent être compilés sous la forme de corpus comparables (textes originaux en chaque langue), tout en exploitant un plus grand nombre de textes de façon beaucoup plus efficace au moyen d’outils adéquats. Toutefois, bien que l’utilisation de corpus soit de plus en plus intégrée dans le flux de travail, certains se montrent encore réticents (Bowker 2004 ; Gallego-Hernández 2015), probablement à cause de la méconnaissance des techniques d’interrogation.
Dans cet article, nous développons un protocole d’interrogation des corpus facilitant la compréhension et la production des termes complexes de l’anglais vers le français et l’espagnol à l’aide de corpus parallèles et comparables. Pour ce faire, nous avons étudié des termes appartenant au domaine de l’environnement, bien que le protocole soit applicable à différents domaines. Nous étudions ce domaine en raison de la sensibilisation croissante à l’environnement et du développement de la base de connaissances terminologiques EcoLexicon (León-Araúz, Reimerink et al. 2019). L’élaboration de cette base de connaissances d’un point de vue terminologique nous a permis de mettre au point des techniques qui sont également utiles aux traducteurs. Dans la section 2, nous examinerons les difficultés de traduction des termes complexes. Par la suite, nous proposerons des techniques d’interrogation de corpus pour régler les problèmes liés à la compréhension et à la production de ces termes (section 3). Enfin, nous présenterons les conclusions dérivées de cette étude et de nouveaux axes de recherche (section 4).
2. Les difficultés des termes complexes
L’identification des équivalents des termes complexes nécessite une analyse syntactico-sémantique exhaustive. D’abord, il est essentiel de délimiter correctement les termes complexes. Cependant, cela n’est pas toujours évident, car ils sont souvent formés par des mots de la langue générale qui peuvent ne pas être considérés comme des unités du terme complexe (p. ex. general dans general circulation model). De plus, la reconnaissance des termes plus longs (p. ex. river water kinetic energy conservation) peut poser des problèmes, puisque certains des formants peuvent ne pas être considérés comme faisant partie du terme complexe ou un seul composé peut parfois être interprété comme plusieurs composés. La proximité entre les termes complexes et les autres unités polylexicales (p. ex. collocations, routines) peut également compliquer la reconnaissance des termes complexes et leur traduction.
D’autre part, la désambiguïsation structurelle (ou bracketing) exige une connaissance approfondie du domaine ainsi que des techniques manuelles ou informatiques (Cabezas-García et León-Araúz 2019). Par exemple, dans offshore wind turbine, offshore modifie wind turbine (offshore [wind turbine]), alors que dans offshore wind report, offshore wind modifie report ([offshore wind] report). Par conséquent, deux unités ou plus (offshore wind) peuvent faire partie d’associations différentes. Ces dépendances ne figurent dans aucune ressource mais peuvent déterminer la forme de l’équivalent dans la langue cible (LC). Par exemple, si nous comprenons offshore wind turbine avec un bracketing incorrect (*[offshore wind] turbine), nous pourrions proposer un équivalent inadéquat (p. ex. turbine de vent maritime en français). C’est pour cela qu’il faut reconstruire le système conceptuel codifié dans le TS (section 3.1).
Connaître le sens des termes complexes entraîne aussi des difficultés en raison de la spécialisation des formants, qui parfois sont omis. Par exemple, stall-regulated wind turbine évoque la régulation de l’éolienne en arrêtant son mouvement. Cependant, les conditions pour que cet arrêt se produise (les vitesses élevées du vent) ne sont pas spécifiées, c’est pourquoi stall-regulated est un formant peu transparent. La relation sémantique entre les formants permet de connaître le sens des termes complexes. Toutefois, cette relation n’est pas explicite et n’est pas toujours facile à inférer. Par exemple, dans oil pollution, pollutionis_caused_byoil, tandis que dans water pollution, pollutionaffectswater (Cabezas-García et Léon-Araúz 2018). Évidemment, cette analyse conceptuelle du terme complexe doit être complétée par une analyse du système conceptuel dans lequel il s’inscrit (section 3.1).
De même, la traduction ou la production des termes complexes dans une autre langue (section 3.2) pose aussi des problèmes car, d’habitude, ces combinaisons n’adoptent pas la même structure dans la LC. Par exemple, les langues germaniques sont plus synthétiques et généralement produisent des composés dont la base est modifiée par des compléments situés à gauche (p. ex. sediment transport rate). La relation sémantique entre les formants est généralement implicite. Au contraire, dans les langues romanes, la base se situe à gauche et ses compléments la suivent (p. ex. énergie éolienne). Dans ces langues, la relation sémantique entre les formants peut être explicitée, par exemple, par les prépositions (pollution par le pétrole). En outre, il n’est pas rare que l’équivalent présente un nombre différent d’éléments, ou même qu’il adopte une structure monolexicale (Cabezas-García 2020).
Une autre difficulté des termes complexes est leur représentation peu systématique dans les ressources (Cabezas-García et Faber 2017) qui, ajoutée à l’absence fréquente d’information conceptuelle, complique l’acquisition des connaissances et l’identification des équivalents. La néologie, très présente dans ces termes, en est l’une des raisons. Par conséquent, le traducteur doit savoir gérer d’autres ressources telles que les corpus.
3. Méthodes d’exploitation des corpus pour la traduction des termes complexes
De nombreuses études ont recherché des techniques de corpus orientées vers la traduction. Par exemple, López et Tercedor (2008) soulignent que l’analyse des concordances a quatre objectifs liés aux différentes étapes de la traduction : 1) extraction d’information conceptuelle ; 2) identification de cooccurrences dans le discours spécialisé ; 3) découverte de la structure argumentative des prédicats ; et 4) identification des différents sens d’un terme. Corpas Pastor (2004) explique qu’à travers l’analyse de corpus on peut extraire des informations très variées sur l’état de la langue de façon rapide. Bermúdez Bausela (2016) défend également l’utilité des corpus pour développer les compétences en traduction des étudiants.
D’autres études ont examiné la traduction des termes complexes au moyen des corpus ainsi que d’autres techniques. Par exemple, Linder (2002) propose des règles pour la traduction des termes complexes en espagnol. Il suggère l’emploi des termes appartenant uniquement à la LC, l’alternance de la préposition de avec d’autres prépositions, la formation de termes complexes qui ne sont pas très longs et l’usage de la transposition. Oster (2003) indique l’existence de tendances de dénomination différentes en allemand et en espagnol pour ce qui est de la forme des termes ainsi que des relations sémantiques internes.
Maniez (2008) utilise les formants dont la traduction est connue combinés avec des opérateurs comme * sur le web. De cette façon, pour traduire gluten-sensitive enteropathy, il cherche « entéropathie * gluten » et obtient les résultats suivants en français : entéropathie au gluten, entéropathie d’intolérance au gluten, entéropathie induite par le gluten et entéropathie de sensibilité au gluten (Maniez 2008 : 163).
Arroyave Tobón et Quiroz Herrera (2012) présentent des techniques pour la traduction des termes complexes de l’anglais vers l’espagnol basées sur l’identification de la relation sémantique interne. Harastani, Daille et al. (2013) remplacent l’adjectif relationnel de termes français tels que cancer pulmonaire par le groupe prépositionnel équivalent (cancer du poumon). Ensuite, ils proposent une traduction compositionnelle du terme complexe en anglais et explorent son occurrence dans un corpus comparable de cette langue. Bien qu’ils obtiennent une précision de 86 %, il y a un grand nombre de termes pour lesquels cette approche ne serait pas valide, par exemple ceux qui ne permettent pas l’alternance adjectif/groupe prépositionnel (p. ex. parc éolien mais *parc de vent).
Kübler, Mestivier et al. (2018) soulignent que de nombreux cas d’erreurs de « distorsion » dans les traductions des étudiants sont dus à une analyse erronée des termes complexes et notamment à une identification erronée de leur base. Elles ont donc conçu une activité destinée à sensibiliser les étudiants à cette question et à suggérer des moyens d’interroger des corpus comparables pour : 1) identifier la base et la structure syntaxique des termes complexes et 2) suggérer les manières les plus appropriées de traduire ces termes.
Idéalement, les études sur les stratégies de corpus et celles portant sur les particularités des termes complexes pourraient être rassemblées afin de faciliter la traduction de ces combinaisons, comme nous le proposons dans cet article. Certains pourraient se demander pourquoi les traducteurs devraient passer leur temps à apprendre une syntaxe difficile pour interroger des corpus alors que le web fournirait les mêmes résultats. Cependant, malgré ses avantages évidents, le web n’est pas conçu comme un outil pour l’analyse linguistique. Les résultats provenant d’un ou plusieurs corpus aideront les traducteurs à faire des choix plus éclairés, puisqu’ils peuvent (entre autres) : 1) extraire des listes de termes, au lieu d’identifier les termes du domaine manuellement ; 2) trier les résultats selon des paramètres différents, comme la fréquence, les métadonnées du corpus, les éléments à gauche et à droite, etc. ; 3) filtrer les occurrences d’une combinaison de termes ; et 4) faire des requêtes plus fines que sur le web (où il n’y a que les opérateurs booléens qui se révèlent utiles, mais insuffisants, pour les traducteurs), comme spécifier le nombre d’éléments parmi des termes différents ou forcer l’apparition d’une catégorie grammaticale. Ce genre d’opérations permet d’acquérir une vision plus large du domaine de spécialité, puisqu’un corpus peut contenir des milliers de textes comparables, alors que les textes consultés sur le web sont souvent moins nombreux et peuvent biaiser les choix des traducteurs.
Les techniques suggérées dans cet article permettent, d’abord, de comprendre les termes complexes (section 3.1) et, ensuite, bien que de façon interdépendante, de les traduire (section 3.2). Les techniques sont proposées dans l’ordre logique des tâches d’analyse et d’après la rapidité de réponse des ressources, bien qu’il soit souvent nécessaire d’en consulter plusieurs dans le but de vérifier et de contraster les solutions trouvées. De surcroît, il est important de remarquer que, bien que les étapes se séparent dans cet article pour des raisons de simplification, dans le flux réel de travail, il est habituel que ces étapes ne se réalisent pas de façon linéaire ni chronologique. Comme indiqué ci-dessous, nous avons utilisé, outre des corpus compilés spécifiquement pour cette recherche, d’autres corpus parallèles choisis parmi les rares disponibles, en raison de leur grand nombre de mots et du fait qu’ils comprennent des textes spécialisés.
3.1. Méthodes pour la compréhension des termes complexes dans la langue source
Bien que la recherche d’équivalence soit souvent la première étape du processus de la traduction, surtout chez les étudiants en traduction, elle doit toujours être précédée d’une phase de compréhension. La compréhension n’est pas un processus cognitif observable. Cependant, Dancette (1997) souligne qu’elle a lieu lorsque l’information linguistique et l’information extralinguistique (c’est-à-dire les connaissances du monde partagées par les spécialistes du domaine) sont mutuellement compatibles. Nous partageons l’avis de Rogers (2015) et défendons que les éléments linguistiques présents dans les corpus permettent d’avoir accès aux connaissances extralinguistiques. Weffer et Suárez (2014) observent l’utilisation de plusieurs stratégies de compréhension des termes complexes adaptées de Dancette (1997) : 1) l’utilisation de connaissances extralinguistiques ; 2) la déverbalisation ; 3) la construction du sens ; 4) l’analyse syntaxique ; 5) l’analyse sémantique ; 6) l’utilisation d’outils visant à la construction du sens (glossaires, corpus, etc.) ; 7) l’identification des relations sémantiques ; 8) l’identification des relations de dépendance syntaxique ; 9) la conceptualisation ; et 10) les correspondances. Elles notent que l’identification de relations sémantiques et de dépendance figure parmi les comportements les moins observés, obtenant de mauvaises correspondances pour certains termes. Elles réitèrent donc la nécessité d’une formation en terminologie pour les traducteurs.
D’abord, nous soulignerons l’importance de reconstruire le système conceptuel évoqué dans le TS complété par des requêtes dans des corpus monolingues. En même temps qu’une connaissance minimale du domaine de spécialité est acquise, les termes complexes sont délimités et la relation que ceux-ci entretiennent est déterminée, sur le plan interne et avec le reste des concepts du même système conceptuel.
3.1.1 Reconstruction d’un système conceptuel ad hoc
Comme le souligne Dancette (2011), avec sa notion d’échafaudage, l’examen du concept dans la structure du domaine est fondamental pour acquérir de nouvelles connaissances. Ainsi, la première étape pour reconstruire un système conceptuel ad hoc consiste à relever les concepts centraux activés dans le TS et à les mettre en relation les uns avec les autres, ainsi qu’avec d’autres dans le domaine, même s’ils ne sont pas explicitement présents dans le texte.
Parfois, le TS lui-même contiendra des patrons de connaissances (marqueurs lexico-syntaxiques qui rendent explicites les relations sémantiques en langage naturel [Meyer 2001]) qui serviront à lancer la procédure. Par exemple, l’extrait suivant (tableau 1) pourrait faire partie d’un TS spécialisé. Il traite de la bottom boundary layer (terme qui ne se trouve pas dans les ressources habituelles) et contient des patrons de causalité (has strong implications in, produced by, influenced by), méronymiques (can be sub-divided into), hyponymiques (namely) et d’autres plus imprécis (between, dominated by, play a dominant role) qui aident à catégoriser et à relier les concepts qu’ils unissent. Par conséquent, avant d’interroger un corpus, nous pouvons relier les concepts du TS dans un premier système comme celui de la figure 1.
Tableau 1
Texte source

Figure 1
Système conceptuel ad hoc de bottom boundary layer
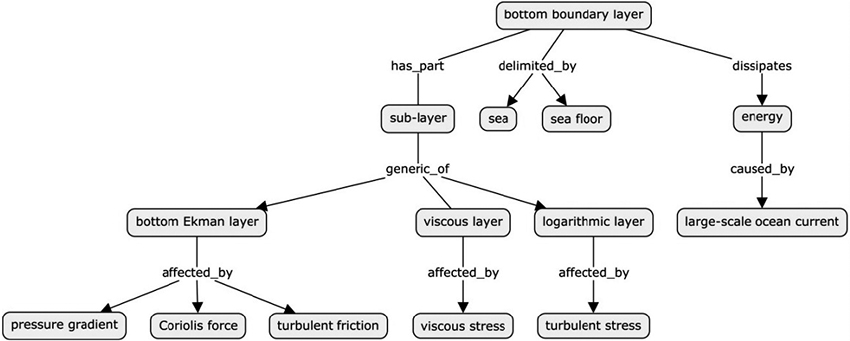
Pourtant, l’établissement de ces relations ne suffira pas et tous les TS ne présenteront pas cette densité de patrons. Ainsi, la prochaine étape consistera à interroger un corpus spécialisé dans la langue source (LS) pour compléter l’« échafaudage » ou la construction des connaissances.
3.1.1.1 Requête du terme complexe
La première requête que nous effectuerons portera sur le terme central du TS : bottom boundary layer. Pour illustrer la procédure, deux corpus disponibles sur Sketch Engine (Kilgarriff, Rychlý et al. 2004) seront interrogés : 1) le corpus anglais EcoLexicon (EEC), d’environ 20 millions de mots (León-Araúz, Reimerink et al. 2019), spécialisé dans l’environnement ; et 2) le DOAJ (Directory of Open Access Journals[1]), qui contient plus de 2 millions de mots sur des textes savants dans divers domaines. L’outil d’analyse de corpus Sketch Engine a été utilisé en raison de ses multiples fonctionnalités, des corpus disponibles et de la possibilité de créer son propre corpus et de mener des requêtes complexes en CQL (Corpus Query Language). Cela permet d’analyser de grandes quantités de textes pour résoudre le problème de la traduction des termes complexes.
Après une requête simple, 303 résultats sont obtenus dans le EEC et 351 dans le DOAJ. Tout d’abord, les résultats peuvent être triés par ordre alphabétique en fonction du premier élément à gauche. On peut ensuite vérifier si les modificateurs les plus fréquents fournissent de nouvelles informations, comme dans le cas de ces termes complexes qui incluent le formant bottom boundary layer : coastal bottom boundary layer, continental shelf bottom boundary layer, current bottom boundary layer, oceanic bottom boundary layer, onshore bottom boundary layer, tidal bottom boundary layer, turbulent bottom boundary layer, wave bottom boundary layer, wave-current bottom boundary layer ou wave-induced bottom boundary layer.
Ces éléments complètent le système conceptuel et rendent compte de ses dimensions de classification : localisation (coastal, continental, onshore, oceanic), cause (wave, puisqu’il est suivi du patron -induced ; et tidal, parce qu’il appartient à une catégorie conceptuelle proche de celle de wave), propriété (turbulent). Cependant, il est nécessaire de vérifier que ces nouveaux éléments, apparemment des sous-types ou des parties, représentent vraiment des concepts différents, c’est-à-dire des hyponymes de bottom boundary layer ou des cohyponymes de bottom Ekman layer, viscous layer et logarithmic layer (figure 1), ou s’ils s’avèrent être des synonymes de ceux-ci, des synonymes entre eux ou même du terme principal.
Par exemple, nous pouvons supposer que wave bottom boundary layer et wave-induced boundarylayer sont des variantes renvoyant au même concept, mais que la dernière explique la relation interne entre wave et bottom boundary layer (la cause). D’autre part, turbulent bottom boundary layer pourrait être une variante de bottom Ekman layer ou de logarithmic layer, puisque les deux semblent liées à turbulence dans le TS lui-même ; ou le terme pourrait également être une variante de bottom boundary layer par transitivité méronymique (le tout hérite des propriétés de ses parties). Du fait de la méconnaissance du domaine, le traducteur doit formuler des hypothèses comme celles-ci lors du processus de compréhension, qui devront être vérifiées ou écartées à travers différentes requêtes.
3.1.1.2 Requête du terme complexe mis en relation avec d’autres termes
Outre l’observation des modificateurs, nous pouvons aussi générer une liste de collocations qui, classées par LogDice, nous renseignent sur d’autres concepts connexes, tels que turbulent et turbulence, présents dans le corpus et dans le TS. Cela, ainsi que les hypothèses précédentes, indique que la relation entre la turbulence et ces couches doit être clarifiée, car les indices fournis par le texte sont insuffisants. Pour ce faire, nous pouvons utiliser la fonctionnalité Filter context, qui consiste à forcer l’apparition de certains mots. Nous recherchons turbulence ou turbulent dans une marge de 15 éléments autour de bottom boundary layer, bottom Ekman layer et logarithmic layer.
Dans le cas de bottom boundary layer (tableau 2), nous constatons qu’il existe une relation de localisation entre turbulence et bottom boundary layer (3), que la turbulence se rapporte au fluide (2), mais que par extension métonymique elle est également attribuée à la bottom boundary layer (1). Par conséquent, il se pourrait que le terme turbulent bottom boundary layer renvoie effectivement à la bottom boundary layer en soulignant sa propriété « turbulente ». Cependant, il existe un extrait (4) qui implique que la bottom boundary layer peut être divisée en une laminar bottom boundary layer et une turbulent bottom boundary layer. L’opposition laminar/turbulent se retrouve souvent dans le corpus et aussi dans les contextes de la requête suivante (tableau 3).
Tableau 2
Extraits du corpus pour bottom boundary layer + turbulence/turbulent

3.1.1.3 Requête des éléments du terme complexe
Aucun des corpus ne donne de résultats lors de la requête de bottom Ekman layer entourée de turbulence ou de turbulent. Dans ces cas, il est utile de décomposer le terme en unités plus gérables, comme Ekman layer, pour laquelle nous trouvons des résultats comme ceux du tableau 3 de même que de multiples occurrences de turbulent Ekman layer. L’opposition laminar/turbulent se produit également dans le contexte d’Ekman layer, ce qui souligne que la turbulence est un critère de classification différent de celui qui motive la subdivision de la bottom boundary layer dans le TS. Comme la Ekman layer peut également être laminar ou turbulent, on ne peut pas dire que le terme turbulent bottom boundary layer en soit le synonyme. En revanche, il existe une autre variante de la Ekman layer (surface layer).
Tableau 3
Extraits du corpus pour Ekman layer + turbulence/turbulent

Dans le cas de logarithmic layer, aucun résultat n’a été obtenu, ni avec la requête du terme complet ni avec celle de son synonyme, transitional layer. Nous écartons donc finalement que turbulent bottom boundary layer soit un synonyme, un cohyponyme ou un hyperonyme de l’un des concepts contenus dans le système conceptuel ad hoc, mais que ce concept renvoie à un autre critère de classification des couches, et que plusieurs d’entre elles, prises ensemble ou séparément, peuvent être turbulentes.
3.1.1.4 Requête des éléments du terme complexe et de l’information métalinguistique
À l’évidence, le système conceptuel qui sous-tend le TS est complexe et multidimensionnel. Afin d’approfondir cette phase de compréhension, nous décomposons le terme de départ et procédons à une requête simple de boundary layer, dont les résultats sont encore réorganisés par ordre alphabétique à gauche et filtrés avec des marqueurs métalinguistiques, tels que term, call, define, definition, word, refer et mean. Nous retrouvons différents types de boundary layer, qui reflètent le plus souvent une dimension de localisation (atmospheric, planetary, urban, low-latitude, marine) ou des propriétés diverses (diabatic, thermal), ce qui indique qu’il s’agit d’un concept superordonné qui est recatégorisé selon la couche de la Terre à laquelle il renvoie.
Parmi ces types, nous trouvons marine boundarylayer et sea bed boundary layer, qui pourraient être synonymes de bottom boundary layer, puisque, d’après l’analyse conceptuelle, nous savons que bottom fait référence au fond marin plutôt qu’à une position inférieure (bottom boundary layerdelimited_bysea floor ; et sea floor est le synonyme de bottom). L’identification des variantes (Pecman 2014 ; Drouin, Francoeur et al. 2017) dans la LS est intéressante pour : 1) retrouver le même concept à partir de deux formes différentes, soit dans le TS, soit dans le corpus, et 2) avoir d’autres termes de départ lors de la recherche d’équivalence (section 3.2). Il en va de même pour les hyponymes ou les cohyponymes, qui peuvent donner des indices sur les conventions utilisées dans leur traduction et donc créer de nouveaux équivalents.
D’autre part, l’information métalinguistique (tableau 4) indique que boundary layer est un terme vaste provenant de la dynamique des fluides (8, 10) et qu’il est appliqué pour délimiter certaines zones dans tout type de fluide en friction avec une surface, tant dans l’atmosphère que dans la mer (9). Par conséquent, lors de la reconstruction du système, des ambiguïtés et des critères de classification différents sont observés, puisque selon la localisation, les couches reçoivent un nom différent sans devenir des concepts totalement distincts (12). De plus, les termes eux-mêmes comportent de nombreuses variations qui illustrent la multidimensionnalité du domaine (León-Araúz, Cabezas-García et al. 2020). Par exemple, la couche faisant référence à l’atmosphère peut être appelée atmospheric boundary layer, air boundary layer, planetary boundary layer, friction layer ou, métaphoriquement, shielding layer (11, 15, 16), ce qui montre l’ensemble dont elle fait partie, le fluide qu’elle contient ou la caractéristique définitoire de la friction. Cependant, il existe des extraits contradictoires, dans lesquels friction layer est classé comme synonyme de planetary boundary layer (11) ou comme une de ses parties (15). En outre, nous constatons que dans la atmospheric boundary layer, il y a également une Ekman layer, qui n’est pas la même dans le contexte de la bottom boundary layer (13), ce qui est confirmé dans l’extrait suivant (14). Le terme (et le concept) boundary layer est donc un exemple illustratif des difficultés que des phénomènes tels que l’imprécision conceptuelle, la multidimensionnalité et la polysémie peuvent causer lors du processus de reconstruction d’un système conceptuel, car les connaissances sont rarement construites sous forme de taxonomies non ambiguës.
Tableau 4
Information métalinguistique sur boundary layer

3.1.1.5 Requête des éléments du terme complexe et des patrons de connaissances
La dernière requête peut être complétée par de nouvelles requêtes en CQL dans lesquelles un terme de départ est accompagné des patrons de connaissances habituels (p. ex. such as, and/or other, type of pour les relations hyponymiques). Il en résulte des contextes riches en connaissances (KRC), qui sont généralement définis comme des contextes contenant au moins un terme explicitement lié à un autre (Meyer 2001). Dancette (2011) affirme que les traducteurs trouvent utile l’accès aux KRC dans les ressources terminologiques. Nous pouvons donc supposer qu’ils trouveront tout aussi utile de disposer de méthodes d’interrogation pour les extraire à partir d’un corpus. Afin de générer des concordances méronymiques comme celles de la figure 2, des requêtes comme celle qui suit seront effectuées, où les lemmes boundary layer sont suivis par un maximum de cinq éléments optionnels et de différents patrons méronymiques (comprise, compose, part, delimit, divide) :
[lemma="boundary"][lemma="layer"][]{0,5}[lemma="comprise|compose|part|delimit|divide"].
Figure 2
Concordances méronymiques de boundary layer

Ces procédures peuvent également être effectuées dans la LC pour détecter d’éventuelles asymétries et des lacunes conceptuelles mais, en général, à partir d’un corpus monolingue, le système conceptuel du TS peut être reconstruit.
3.1.2 Interprétation structurale et sémantique des termes complexes
Dans le cas des termes complexes de deux formants, la relation interne peut souvent être déduite si la signification et la catégorie conceptuelle de chaque élément sont connues, ainsi que le potentiel de combinaison des deux catégories dans le domaine. Par exemple, sans qu’il soit nécessaire de faire une recherche, nous saurons que, dans sea floor, une relation méronymique est encodée (floor part_of sea). Ce terme présente la structure N+N, mais dans les termes A+N l’adjectif peut encoder les propriétés d’une entité (viscous layer) ou la relation entre deux concepts (turbulent stress, turbulencecausesstress), qu’il est nécessaire d’analyser ou de décoder à l’aide du corpus. Lorsqu’il s’agit de composés A+N, nous avons souvent tendance à traiter l’adjectif comme une propriété ou même comme un modificateur indépendant de la structure du composé, ce qui peut générer des calques. Avant de chercher l’équivalence, il est important de savoir si l’adjectif encode une relation ou une propriété. Dans le cas de turbulent stress, il convient d’effectuer une recherche, en filtrant à nouveau par contexte, dans laquelle stress et turbulence apparaissent sémantiquement liés. Avec des concordances comme celles de la figure 3, les patrons driven by, generated by, induced by, leads to et due to rendent explicite la relation encodée et sa directionnalité : turbulence causesstress.
Figure 3
Concordances causales entre stress et turbulence

Dans le cas des termes de trois ou plus constituants, avant de déduire les relations encodées, il est nécessaire d’effectuer une série d’opérations conduisant à la désambiguïsation structurelle ou bracketing. Pour bottom boundary layer, il serait nécessaire de savoir si bottom dépend davantage de boundary ou de layer. Sans cela, son interprétation, et donc la recherche d’équivalence, pourrait être erronée. En outre, bottom est sémantiquement ambigu (3.1.1.4). Pour la désambiguïsation structurelle, la technique la plus efficace (bien qu’il y en ait plusieurs, Cabezas-García et León-Araúz 2019) serait de décomposer le terme en autant de groupes que possible et d’en comparer la fréquence dans un corpus. Les requêtes suivantes seraient effectuées :
[tag!="JJ.*|N.*"][lemma="bottom"][lemma="boundary"][tag!="N.*|JJ.*"]within <s/>
[tag!="JJ.*|N.*"][lemma="boundary"][lemma="layer"][tag!="N.*|JJ.*"]within <s/>
[tag!="JJ.*|N.*"][lemma="bottom"][lemma="layer"][tag!="N.*|JJ.*"]within <s/>.
Ces requêtes recherchent les paires bottom boundary, boundary layer et bottom layer dans une seule phrase (within </s>), précedés de tout élément autre qu’un adjectif ou un nom ([tag!="N.*|JJ.*"]), afin d’éviter des termes plus longs dans lesquels ces paires interviennent. Selon le critère de la contiguïté (adjacency), si la combinaison bottom boundary donne plus de résultats que boundary layer, le bracketing sera effectué à gauche ([bottom boundary] layer). Selon le critère de dépendance, si bottom layer produit plus de résultats que boundary layer, le bracketing sera effectué à droite (bottom [boundary layer]). Les résultats de ces trois requêtes, en ajoutant ceux des deux corpus (tableau 5), indiquent clairement que le bracketing est bottom [boundary layer], parce que la combinaison boundary layer est plus fréquente que les autres combinaisons possibles (bottom boundary et bottom layer). Cela confirme les deux critères dans les deux corpus.
Tableau 5
Résultats des requêtes pour établir le bracketing de bottom boundary layer

Une fois que la relation de dépendance sera clarifiée, il sera nécessaire d’établir la relation sémantique encodée entre bottom et boundary layer. Comme dans le cas de turbulent stress, nous pouvons rechercher boundary layer (cette fois-ci en excluant bottom du début du terme : [tag!="bottom"][lemma="boundary"][lemma="layer"]) et bottom dans la même phrase dans le but d’observer si des patrons de connaissances apparaissent entre eux. En outre, comme nous savons déjà que bottom fait référence au fond marin et que celui-ci peut également être appelé (sea/ocean) floor ou (sea) bed, nous inclurons ces termes dans la fonctionnalité Filter context, de sorte que nous obtiendrons les résultats suivants (figure 4) et confirmerons qu’entre bottom et boundary layer, il existe une relation sémantique de localisation exprimée à travers des patrons tels que near, over, at, formed along, generated near et above.
Figure 4
Concordances pour inférer la relation entre boundary layer et bottom

3.2 Méthodes pour la production des termes complexes dans la langue cible
Les corpus sont aussi utiles pour la recherche d’équivalences de termes complexes. Des méthodes d’interrogation de corpus parallèles et monolingues sont présentées dans les sections 3.2.1 et 3.2.2. Dans cette procédure, nous commençons par les options les plus immédiates (comme les traductions linéaires ou compositionnelles) pour parvenir à d’autres options plus sophistiquées, qui peuvent révéler des équivalences plus éloignées du point de vue formel et sémantique (p. ex. des requêtes conceptuelles). Les requêtes suivantes sont illustrées avec le terme de départ (bottom boundary layer) et d’autres termes environnementaux, puisque toutes les étapes de la procédure ne servent pas nécessairement à trouver l’équivalence d’un même terme. Par exemple, les corpus parallèles n’offrent pas d’occurrences de bottom boundary layer.
3.2.1 Requête d’équivalents dans des corpus parallèles
Les corpus parallèles offrent des solutions de traduction plus directes que les corpus comparables, c’est pourquoi les traducteurs les consultent souvent en premier. Nous utilisons quatre corpus parallèles : 1) les corpus OPUS2 English-Spanish et 2) OPUS2 English-French (Tiedemann 2012), de libre accès sur Sketch Engine et organisés en sous-corpus (Banque centrale européenne, Parlement européen, etc.) ; ainsi que 3) les corpus EurLex English-Spanish et 4) EurLex English-French (Baisa, Michelfeit et al. 2016), qui incluent des textes de la base de données EUR-Lex. Idéalement, pour ce qui suit, il faudrait consulter des corpus parallèles propres au domaine environnemental ; cependant, ce type de corpus est rare, voire inexistant. Nous montrons donc la réalité que trouvent les traducteurs, qui doivent chercher des réponses dans les ressources disponibles.
3.2.1.1 Requête du terme complexe
Étant donné que les corpus parallèles sont formés par des TS alignés avec leurs TC, il est logiquement possible de chercher le terme complexe dans la LS et de le retrouver aligné avec ses équivalents. Pour ce faire, nous devons sélectionner l’option Parallel Concordance sur Sketch Engine et choisir le corpus souhaité.
Malheureusement, cette requête ne peut pas être illustrée par l’exemple de bottom boundary layer, parce que les corpus disponibles ne montrent pas d’occurrences. Le terme long range transboundary air pollution servira à illustrer la procédure ainsi que la prolifération de variantes terminologiques dans les corpus parallèles. Si nous trouvons plusieurs équivalences, il faudra en vérifier la validité en évaluant la fréquence ou le type de textes et contextes d’usage, entre autres. Ces questions pourront être consultées aussi bien dans le corpus parallèle que sur Google Scholar, car cette ressource peut fournir de plus amples informations tirées de textes spécialisés. Par exemple, long-range transboundary air pollution désigne l’introduction dans l’atmosphère par l’homme de substances ayant une action nocive dans un autre pays et pour laquelle il n’est pas possible de distinguer les apports des sources individuelles ou des groupes de sources d’émission. Ce terme présente les équivalents suivants (tableau 6) dans les corpus parallèles en espagnol et en français, qui figurent dans des textes spécialisés produits par le Parlement européen ou les Nations unies, entre autres organisations, ainsi que sur Google Scholar.
Le tableau 6 montre que les équivalents de long-range transboundary air pollution les plus utilisés en espagnol sont les variantes 1 et 2, ce qui est confirmé dans les trois ressources. Cependant, il faut savoir détecter les erreurs de traduction, qui se produisent souvent dans les corpus parallèles, car ceux-ci représentent des cas réels (et donc aussi des erreurs) de traduction. La fréquence réduite de contaminación atmosférica transfronteriza prolongada pourrait en être un exemple.
Par rapport au français, on observe un grand nombre de variantes, dont la première est la plus fréquente dans les trois ressources. D’autres termes sont également très utilisés, comme la variante 2, la variante 6 (145 occurrences sur Google Scholar, mais fréquence inférieure dans OPUS2, incluant aussi des textes généraux) ou encore la variante 10. Les autres équivalents ont entre 0 et 9 occurrences sur Google Scholar et des chiffres également réduits dans les corpus parallèles. Cependant, il faut noter que la présence d’autres termes à haute fréquence (p. ex. les variantes 3 et 9) n’a pas pu être validée sur Google Scholar car cette ressource ne permet pas de limiter les recherches de façon aussi précise que les expressions régulières. Par exemple, dans le cas de la variante 3, le chiffre de Google Scholar inclut les occurrences de pollution atmosphérique transfrontière aussi bien que de pollution atmosphérique transfrontière à longue distance, entre autres. En somme, la recherche d’équivalents en français et en espagnol de ce terme aurait été pratiquement résolue avec cette étape, puisqu’il suffirait de discriminer les usages des variantes les plus fréquentes en fonction de critères tels que la typologie ou le style discursif du texte, son origine géographique ou institutionnelle.
Tableau 6
Équivalents espagnols et français de long-range transboundary air pollution obtenus à l’aide de la requête du terme complexe (corpus parallèles) ainsi que sur Google Scholar, et leurs occurrences

3.2.1.2 Requête des éléments du terme complexe
Si les équivalents ne sont pas trouvés ou s’il faut chercher d’autres solutions, une requête des éléments du terme sert à explorer leurs traductions ainsi que leurs combinaisons fréquentes. Revenant au terme de départ, rechercher la combinaison qui agit comme base (boundary layer) dans des corpus parallèles peut éclairer les conventions couramment utilisées pour la traduction du terme, soit en tant que terme de deux formants soit en tant que base d’autres termes complexes. Par exemple, les figures 5 et 6 montrent les équivalences en espagnol de boundary layer (límite, capa límite), benthic boundary layer (capa bentónica limítrofe, capa del límite bentónico) et planetary boundary layer (capa limítrofe del planeta). Comme nous le montrerons dans les sections suivantes, ces équivalences ne sont pas toujours précises (p. ex. capa del límite bentónico est le résultat d’une mauvaise désambiguïsation structurelle, puisque benthonic modifie layer plutôt que boundary) et montrent des permutations morphosyntaxiques qu’il faudrait vérifier dans des corpus monolingues (section 3.2.2) (capa limítrofe del planeta vs capa bentónica limítrofe). Néanmoins, nous pouvons retenir que capa límite ou capa limítrofe seront des équivalents possibles de boundary layer. En français, les figures 7 et 8 montrent les équivalences de boundary layer (couche limite), marineboundary layer (couche limite marine), planetary boundarylayer (couche limite planétaire) et benthic boundary layer (couche limite benthique), ce qui suggère que la base de l’équivalent français sera couche limite.
Figure 5
Concordances parallèles (EN-ES) de boundary layer dans le corpus OPUS2

Figure 6
Concordances parallèles (EN-ES) de boundary layer dans le corpus EurLex

Figure 7
Concordances parallèles (EN-FR) de boundary layer dans le corpus OPUS2

Figure 8
Concordances parallèles (EN-FR) de boundary layer dans le corpus EurLex

3.2.2 Requête d’équivalents dans des corpus monolingues
La recherche d’équivalents dans les corpus monolingues ou comparables est moins directe que la recherche dans les corpus parallèles. Toutefois, son utilisation se justifie par la qualité des textes (qui sont rédigés originalement dans la langue en question, montrent des usages réels et évitent, en principe, les erreurs de traduction) et la facilité d’obtenir un tel corpus, les parallèles étant beaucoup moins fréquents. Les requêtes ci-dessous ont été effectuées sur le corpus d’EcoLexicon en espagnol, d’environ 10 millions de mots sur l’environnement, et un corpus en français d’environ 12 millions de mots sur l’environnement, spécifiquement compilé pour cette étude.
3.2.2.1 Requête du terme complexe
D’abord, nous pouvons consulter la traduction compositionnelle ou linéaire du terme complexe, en utilisant des marges possibles entre les formants, ainsi que des mots tronqués (p. ex. crea.* pour les formes espagnoles crear, creación, etc.). Dans le cas de bottom boundary layer (analysé conceptuellement dans la section 3.1), la traduction du terme complexe pourrait être consultée comme suit (espagnol et français) :
[lemma="capa"][]{0,4}[lemma="límite|limítrofe"][]{0,4}[lemma="fondo"]within <s/>
[lemma="couche"][]{0,4}[lemma="limite|limitrophe"][]{0,4}[lemma="fond"]within <s/>
Plus précisément, nous recherchons la base (capa et couche) (ES : [lemma="capa"] ; FR : [lemma="couche"]), suivie d’une marge de 0 à 4 éléments ([]{0,4}), des lemmes límite/limítrofe ou limite/limitrophe (ES : [lemma="límite|limítrofe"] ; FR : [lemma="limite|limitrophe"]), d’une autre marge de 0 à 4 mots et, finalement, du lemme fondo en espagnol et fond en français (ES : [lemma="fondo"] ; FR : [lemma="fond"]), le tout dans la même phrase (within <s/>). Cette requête permet d’obtenir des solutions de traduction (figures 9 et 10) : capa límite de fondo, capa límite del fondo,capa límite del fondo marino, capa límite del fondo del océano costero ; couche limite de fond, couche limite du fond, couche limite sur le fond marin. D’après le critère de la fréquence, il apparaît que les variantes les plus utilisées en espagnol et en français seraient capa límite de fondo et couche limite de fond. En espagnol, aucune occurrence de capa limítrofe n’apparaît, comme les corpus parallèles ont suggéré, ce qui met en valeur les corpus monolingues.
Figure 9
Équivalents espagnols de bottom boundary layer

Figure 10
Équivalents français de bottom boundary layer

L’insertion des marges entre les formants du terme permet souvent d’obtenir des variations morphosyntaxiques (capa límite de fondo, capa límite del fondo [marino], couche limite de fond, couche limite du fond [marin]), mais aussi de nouveaux termes du domaine qui pourraient être inclus dans le TS, comme c’est le cas de capa límite de Ekman de fondo, capa viscosa, capa límite de fondo laminar, couche limite turbulente ou couche limite de surface). De même, nous pouvons établir d’autres équivalences dans le TS grâce à l’observation des termes à gauche et à droite du terme de départ, comme fricción, lecho (marino), capa logarítmica, capa límitesuperficial, couche d’Ekman de fond, turbulence, cisaillement, etc.
3.2.2.2 Requête des éléments du terme complexe
Comme dans les corpus parallèles, une autre méthode pour trouver des équivalents, si nous ne connaissions pas les équivalents de tous les formants (ce qui est le cas en 3.2.2.1), consiste à effectuer des recherches en disséquant les éléments du terme complexe. Par exemple, pour bottom boundary layer, en fonction des résultats obtenus aux étapes précédentes, nous pourrions connaître les équivalents de bottom et layer ou ceux de boundary layer.
Les requêtes suivantes fournissent des contextes où : 1) capa ou couche ([lemma="capa"] ; [lemma="couche"]) sont suivis d’éléments inconnus ([]{1,4}) et de fondo ou fond ([lemma="fondo" ; [lemma="fond"]) ; et 2) capa ou couche sont suivis de límite ou limite et d’éléments inconnus suivis d’un nom [tag="N.*"].
(1) [lemma="capa"][]{1,4}[lemma="fondo"]within <s/>
(2) [lemma="capa"][lemma="límite"][]{0,4}[tag="N.*"]within <s/>(1) [lemma="couche"][]{1,4}[lemma="fond"]within <s/>
(2) [lemma="couche"][lemma="limite"][]{0,4}[tag="N.*"]within <s/>
La première requête (figures 11 et 12) confirme les résultats obtenus dans la section 3.2.2.1 (capa límite de/del fondo ; couche limite de/du fond). Cependant, nous observons aussi que parfois le formant boundary est omis dans les équivalents espagnols (capa de fondo), notamment dans les termes à quatre formants, en espagnol et en français (capa de Ekman de fondo, plûtot que capa límite de Ekman de fondo ; et capa logarítmica de fondo, couche d’Ekman de fond). En français nous observons aussi des variantes qui rendent explicite la relation entre la couche limite et le fond : couche d’Ekman au voisinage du fond, couche limite turbulente près du fond, couche limite turbulente sur le fond marin, couche limite près du fond.
Figure 11
Résultats de la requête (1) dans le corpus EcoLexicon espagnol

Figure 12
Résultats de la requête (1) dans le corpus français sur l’environnement

Cependant, la deuxième requête (figures 13 et 14) génère plus de bruit, car le corpus contient de nombreuses occurrences des termes portant la base couche limite (plus de mille concordances).
Figure 13
Résultats de la requête (2) dans le corpus EcoLexicon espagnol

Figure 14
Résultats de la requête (2) dans le corpus français sur l’environnement

Étant donné que grâce à l’analyse conceptuelle nous savons que la bottom boundary layer est située dans la mer, nous pouvons encore filtrer les concordances avec l’option Filter context et réduire le bruit en utilisant les termes mar et océano comme filtres dans une distance ±15 (figure 15).
Figure 15
Résultats de la requête (2) après l’utilisation des filtres mar et océano dans le corpus EcoLexicon espagnol

3.2.2.3. Requête conceptuelle
Si la requête précédente n’a pas permis de connaître l’équivalent (probablement parce qu’il ne s’agit pas d’une traduction linéaire), des recherches conceptuelles qui révèlent des correspondances moins littérales peuvent être utiles. Celles-ci consistent à rechercher un élément non présent dans le terme complexe mais qui entretient une relation sémantique claire avec le concept d’origine.
Étant donné que bottom boundary layer présente une équivalence linéaire en français et en espagnol, les avantages de cette requête peuvent être mieux illustrés avec un autre terme environnemental caractérisé par une traduction non linéaire et de multiples variantes terminologiques : low-level ozone.
Ce terme pourrait poser des problèmes parce qu’un non-spécialiste pourrait penser, dans un premier temps, que low-level ozone désigne des quantités réduites de ce gaz, mais une analyse conceptuelle basée sur des extraits comme celui du tableau 7 révèle que low-level fait allusion au niveau de l’atmosphère dans lequel se trouve ce type d’ozone : la troposphère, ce qui est omis dans le terme de départ mais pas dans sa variante ozone troposphérique.
Tableau 7
Extrait du corpus pour low-level ozone

De même, pendant la phase de compréhension, nous apprenons que les composés organiques volatils influencent la formation de low-level ozone. Par conséquent, nous pouvons effectuer une requête incluant : 1) ces composés (dont le nom en espagnol et en français est connu : compuestos orgánicos volátiles, COV ou VOC, par son acronyme en anglais ; et composés organiques volatils, COV ou VOC) et 2) les différentes formes que peut prendre la relation qu’ils codifient avec low-level ozone (p. ex. en français, les patrons de connaissances ils forment, contribuent à la formation de, interviennent dans la formation de, provoquent la formation de, participent à la formation de, favorisent la création de, etc.). De cette façon, nous espérons que le corpus révélera l’équivalent de low-level ozone dans la LC. Les requêtes pourraient être les suivantes (espagnol et français) :
(([lemma="compuesto"][lemma="orgánico"][lemma="volátil"]|[lemma="COV|VOC"])[]{0,5}[lemma="crea.*|produc.*|form.*|gener.*|contribu.*|influ.*|ocasionar"][]{0,5}[tag="N.*"])|([tag="N.*"][]{0,5}[lemma="crea.*|produc.*|form.*|gener.*|contribu.*|influ.*|ocasionar"][]{0,5}([lemma="compuesto"][lemma="orgánico"][lemma="volátil"]|[lemma="COV|VOC"]))
(([lemma="composé"][lemma="organique"][lemma="volatil"]|[lemma="COV|VOC"])[]{0,5}[lemma="cré.*|produ.*|form.*|génér.*|contribu.*|influ.*|occasioner|intervenir|provoquer|participer|favoris.*"][]{0,5}[tag="N.*"])|([tag="N.*"][]{0,5}[lemma="cré.*|produ.*|form.*|génér.*|contribu.*|influ.*|occasioner|intervenir|provoquer|participer|favoris.*"][]{0,5}([lemma="composé"][lemma="organique"][lemma="volatil"]|[lemma="COV|VOC"]))
Tout d’abord, avec la séquence en gras nous recherchons les traductions de volatile organic compound en espagnol (première requête) et en français (deuxième requête), suivies d’une marge de 0 à 5 éléments ([]{0,5}). Ensuite, la séquence soulignée fait référence aux principales formes que peut acquérir la relation, dans lesquelles nous utilisons des mots tronqués pour obtenir différentes formes grammaticales d’une même racine (p. ex. génér.*, produ.*). Enfin, nous incluons une autre marge de 0 à 5 éléments et un nom (marqué en gras), puisque l’équivalent de low-level ozone aura probablement cette catégorie.
Grâce à cette requête, nous obtenons des équivalents possibles (tableau 8, soulignés), car leur contenu conceptuel coïncide avec celui du terme en LS. Cependant, bien que certaines de ces coïncidences ne permettent pas trouver exactement l’équivalent, elles fournissent également des indices pour poursuivre la recherche, p. ex. ozono en los primeros 10 a 15 km por encima del suelo (troposfera). Bien entendu, la validité de ces solutions de traduction dépend de la situation communicative de chaque traduction particulière.
Tableau 8
Échantillon des résultats de la requête conceptuelle de low-level ozone

Il convient de noter que l’usage d’un concept de départ (c’est-à-dire les composés organiques volatils dans cet exemple) très général (p. ex. vent) amène souvent du bruit, c’est pourquoi nous recommandons d’utiliser des concepts plus spécifiques. Ces requêtes peuvent partir de n’importe quel élément de définition (hyper- ou hyponyme, parties, causes, fonctions, lieux, etc.), accompagné des patrons de connaissances qui expriment habituellement ces relations.
Il faut aussi souligner qu’une requête conceptuelle permet souvent d’obtenir plusieurs variantes qui seraient autrement masquées, comme c’est le cas de low-level ozone, qui peut être traduit en français par ozone dans la basse atmosphère, ozone de la basse atmosphère, ozone troposphérique, ozone au niveau du sol, ozone dans la troposphère, ozone de la troposphère ou même mauvais ozone.
4. Conclusions
Nous avons proposé un protocole destiné à faciliter la gestion des termes complexes, développant ainsi les compétences des traducteurs et évitant les erreurs de traduction qui sont souvent le résultat d’un manque d’informations, d’une méconnaissance des techniques de requête ou de ressources terminologiques peu systématiques. Il s’agit donc d’un protocole qui peut être appliqué par tous les types de traducteurs (professionnels, bénévoles, spécialisés dans un ou plusieurs domaines, etc.), notamment par ceux qui travaillent avec des textes scientifiques et techniques. Bien qu’il prenne du temps, ce protocole permet de prendre des décisions éclairées sur les types et les degrés d’équivalence. Par conséquent, nous espérons éveiller l’intérêt des traducteurs pour les corpus, qu’ils suivent ou non les lignes directrices proposées. En effet, ce protocole n’est pas conçu comme le seul modèle à suivre, mais comme un guide de techniques qui peuvent être utilisées et combinées selon les besoins du contexte de la traduction.
Bien que certaines limitations puissent être rencontrées (p. ex. la nécessité d’apprentissage de la part des traducteurs des techniques d’interrogation des corpus ou l’accès difficile à certains corpus), ce protocole peut être adapté à différentes situations. En outre, les corpus remplacent, avec une plus grande garantie de succès, la consultation longue de textes parallèles, qui a fait son temps, de sorte que la linguistique des corpus apparaît comme une nécessité dans la formation des traducteurs.
D’autre part, le fait que certaines de ces démarches n’aient pas permis de trouver l’équivalent ne fait que souligner la réalité de ces types de termes, pour lesquels il n’existe souvent pas d’équivalent établi, mais qui sont plutôt transférés avec différents types d’explications et avec beaucoup de variations. Le traducteur doit donc faire preuve de prise de décision et d’une autonomie totale (fondée évidemment sur les tendances observées), car il devra fréquemment intervenir dans la production de l’équivalent. Pour ce faire, il peut compter sur les outils et les indices fournis par les corpus. Lors d’études ultérieures, nous avons l’intention de mettre en oeuvre ce protocole dans l’enseignement de la traduction et d’évaluer les résultats de son application en comparant les résultats (en termes de temps et de qualité) obtenus avec les méthodes plus traditionnelles. En outre, il sera appliqué à d’autres unités telles que les collocations verbales.
Appendices
Remerciements
Cette recherche a été réalisée dans le cadre des projets PID2020-118369GB-I00 (ministère de la Science et de l’Innovation espagnol) et A-HUM-600-UGR20 (Gouvernement régional d’Andalousie).
Note
-
[1]
Directory Open Access Journals (2022) : DOAJ corpus. Disponible sur Sketch Engine (https://app.sketchengine.eu/).
Bibliographie
- Arroyave Tobón, Alejandro et Quiroz Herrera, Gabriel (2012) : Consideraciones didácticas para la enseñanza de sintagmas nominales con premodificación compleja del inglés al español. Núcleo. 29 :179-215.
- Baisa, Vit, Michelfeit, Jan, Medved, Marek et al. (2016) : European Union Language Resources in Sketch Engine. In : Nicoletta Calzolari, Khalid Choukri, Thierry Declerck, dir. Proceedings of the 10th International Conference on Language Resources and Evaluation (LREC 2016). Portorož : ELRA, 2799-2803.
- Bermúdez Bausela, Montserrat (2016) : The importance of corpora in translation studies : a practical case. In : Antonio Pareja-Lora, Cristina Calle-Martínez et Pilar Rodríguez-Arancón, dir. New Perspectives on Teaching and Working with Languages in the Digital Era. Dublin : Research-publishing.net, 363-374.
- Bowker, Lynne (2004) : Corpus resources for translators : academic luxury or professional necessity ? TradTerm. 10:213-247.
- Cabezas-García, Melania (2020) : Los términos compuestos desde la Terminología y la Traducción. Berlin : Peter Lang.
- Cabezas-García, Melania et Faber, Pamela (2017) : A Semantic Approach to the Inclusion of Complex Nominals in English Terminographic Resources. In : Ruslan Mitkov, dir. Computational and Corpus-Based Phraseology, Lecture Notes in Computer Science 10596. Cham : Springer, 145-159.
- Cabezas-García, Melania et León-Araúz, Pilar (2018) : Towards the Inference of Semantic Relations in Complex Nominals : a Pilot Study. In : Nicoletta Calzolari, Khalid Choukri, Christopher Cieriet al., dir. Proceedings of the 11th International Conference on Language Resources and Evaluation (LREC 2018). Miyazaki : ELRA, 2511-2518.
- Cabezas-García, Melania et León-Araúz, Pilar (2019) : On the structural disambiguation of multi-word terms. In : Gloria Corpas Pastor et Ruslan Mitkov, dir. Computational and Corpus-Based Phraseology, Lecture Notes in Computer Science 11755. Cham : Springer, 46-60.
- Corpas Pastor, Gloria (2004) : La traducción de textos médicos especializados a través de recursos electrónicos y corpus virtuales. In : Luis González et Pollux Hernúñez, dir. Las palabras del traductor. Actas del II Congreso Internacional “El español, lengua de traducción”. Bruxelles : Commission européenne, ESLETRA, 137-164.
- Dancette, Jeanne (1997) : Mapping Meaning and Comprehension in Translation. In : Joseph H. Danks, Gregory M. Shreve, Stephen B. Fountainet al., dir. Cognitive Processes in Translation and Interpreting. Londres : Sage Publications, 77-103.
- Dancette, Jeanne (2011) : L’intégration des relations sémantiques dans les dictionnaires spécialisés multilingues : du corpus ciblé à l’organisation des connaissances. Meta. 56(2):284-300.
- Drouin Patrick, Francoeur, Aline, Humbley, John et al., dir. (2017) : Multiple Perspectives on Terminological Variation. Amsterdam/Philadelphie : John Benjamins.
- Gallego-Hernández, Daniel (2015) : The use of corpora as translation resources : A study based on a survey of Spanish professional translators. Perspectives. 23(3):375-391.
- Harastani, Rima, Daille, Béatrice et Morin, Emmanuel (2013) : Identification, alignement, et traductions des adjectifs relationnels en corpus comparables. In : Emmanuel Morin et Yannick Estève, dir. Vingtième conférence du Traitement Automatique du Langage Naturel 2013 (TALN 2013). Sables d’Olonne : ATALA, 313-326.
- Kilgarriff, Adam, Rychlý, Pavel, Smrz, Pavel et al. (2004) : The Sketch Engine. In : Geoffrey Williams et Sandra Vessier, dir. Proceedings of the 11th EURALEX International Congress. Lorient : Euralex, 105-115.
- Kübler, Natalie, Mestivier, Alexandra et Pecman, Mojca (2018) : Teaching Specialised Translation Through Corpus Linguistics : Translation Quality Assessment and Methodology Evaluation and Enhancement by Experimental Approach. Meta. 63(3):807-825.
- Linder, Daniel (2002) : Translating noun clusters and ‘nounspeak’ in specialized computer text. In : José Chabás, Rolf Gaser et Joëlle Rey, dir. Translating Science. Barcelone : Universitat Pompeu Fabra, 261-270.
- León-Araúz, Pilar, Cabezas-García, Melania et Reimerink, Arianne (2020) : Representing Multiword Term Variation in a Terminological Knowledge Base : a Corpus-Based Study. In : Nicoletta Calzolariet al., eds. Proceedings of the 12th Conference on Language Resources and Evaluation (LREC 2020). Marseille : ELRA, 2351-2360.
- León-Araúz, Pilar, Reimerink, Arianne et Faber, Pamela (2019) : EcoLexicon and by-products : integrating and reusing terminological resources. Terminology. 25(2):222-258.
- Loock, Rudy (2016) : L’utilisation des corpus électroniques chez le traducteur professionnel : quand ? comment ? pour quoi faire ? ILCEA [En ligne]. 27. http://journals.openedition.org/ilcea/3835.
- López, Clara Inés et Tercedor, Maribel (2008) : Corpora and students’ autonomy in scientific and technical translation training. The Journal of Specialised Translation. 9:2-19.
- Maniez, François (2008) : Using the Web and computer corpora as language resources for the translation of complex noun phrases in medical research articles. Panace@. 8(26):162-167.
- Meyer, Ingrid (2001) : Extracting knowledge-rich contexts for terminography. A conceptual and methodological framework. In : Didier Bourigault, Christian Jacquemin et Marie-Claude L’Homme, dir. Recent Advances in Computational Terminology. Amsterdam/Philadelphie : John Benjamins, 279-302.
- Oster, Ulrike (2003) : Los términos de la cerámica en alemán y en español. Análisis semántico orientado a la traducción de los compuestos nominales alemanes. Thèse de doctorat. Castellón : Universitat Jaume I.
- Pecman, Mojca (2014) : Variation as a cognitive device : how scientists construct knowledge through term formation. Terminology. 20(1):1-24.
- Rogers, Margaret (2015) : Specialised Translation. Shedding the ‘Non-Literary’ Tag. Londres : Palgrave Macmillan.
- Tiedemann, Jörg (2012) : Parallel data, tools and interfaces in OPUS. In : Nicoletta Calzolari, Khalid Choukri, Thierry Declercket al., dir. Proceedings of the 8th International Conference on Language Resources and Evaluation (LREC 2012). Istanbul : ELRA, 2214-2218.
- Weffer, Elizabeth et Suárez, María Mercedes (2014) : Traducción de sintagmas nominales extensos especializados (SNEE) en un corpus de cambio climático. Lenguaje. 42(1):125-142.
 10.7202/1006177ar
10.7202/1006177arList of figures
Figure 1
Système conceptuel ad hoc de bottom boundary layer
Figure 2
Concordances méronymiques de boundary layer
Figure 3
Concordances causales entre stress et turbulence
Figure 4
Concordances pour inférer la relation entre boundary layer et bottom
Figure 5
Concordances parallèles (EN-ES) de boundary layer dans le corpus OPUS2
Figure 6
Concordances parallèles (EN-ES) de boundary layer dans le corpus EurLex
Figure 7
Concordances parallèles (EN-FR) de boundary layer dans le corpus OPUS2
Figure 8
Concordances parallèles (EN-FR) de boundary layer dans le corpus EurLex
Figure 9
Équivalents espagnols de bottom boundary layer
Figure 10
Équivalents français de bottom boundary layer
Figure 11
Résultats de la requête (1) dans le corpus EcoLexicon espagnol
Figure 12
Résultats de la requête (1) dans le corpus français sur l’environnement
Figure 13
Résultats de la requête (2) dans le corpus EcoLexicon espagnol
Figure 14
Résultats de la requête (2) dans le corpus français sur l’environnement
Figure 15
Résultats de la requête (2) après l’utilisation des filtres mar et océano dans le corpus EcoLexicon espagnol
List of tables
Tableau 1
Texte source
Tableau 2
Extraits du corpus pour bottom boundary layer + turbulence/turbulent
Tableau 3
Extraits du corpus pour Ekman layer + turbulence/turbulent
Tableau 4
Information métalinguistique sur boundary layer
Tableau 5
Résultats des requêtes pour établir le bracketing de bottom boundary layer
Tableau 6
Équivalents espagnols et français de long-range transboundary air pollution obtenus à l’aide de la requête du terme complexe (corpus parallèles) ainsi que sur Google Scholar, et leurs occurrences
Tableau 7
Extrait du corpus pour low-level ozone
Tableau 8
Échantillon des résultats de la requête conceptuelle de low-level ozone